There are many flavours of event-driven architecture. I tend to speak and write a lot about event choreography, as 1) it’s a pattern that allows for effective separation of concerns, and 2) it’s a more accessible introduction to event-driven architectures than things like event sourcing. (Although I do make noise about event sourcing, too.)
In particular, in-process event choreography is extremely useful as it allows different parts of the same codebase to take action without being directly coupled together, but still allows for all of the state changes to be committed within a single transaction. Similarly, for distributed systems, event choreography is a powerful pattern to deliver simple, scalable workflows across disparate parts of an organisation.
Choreography versus orchestration
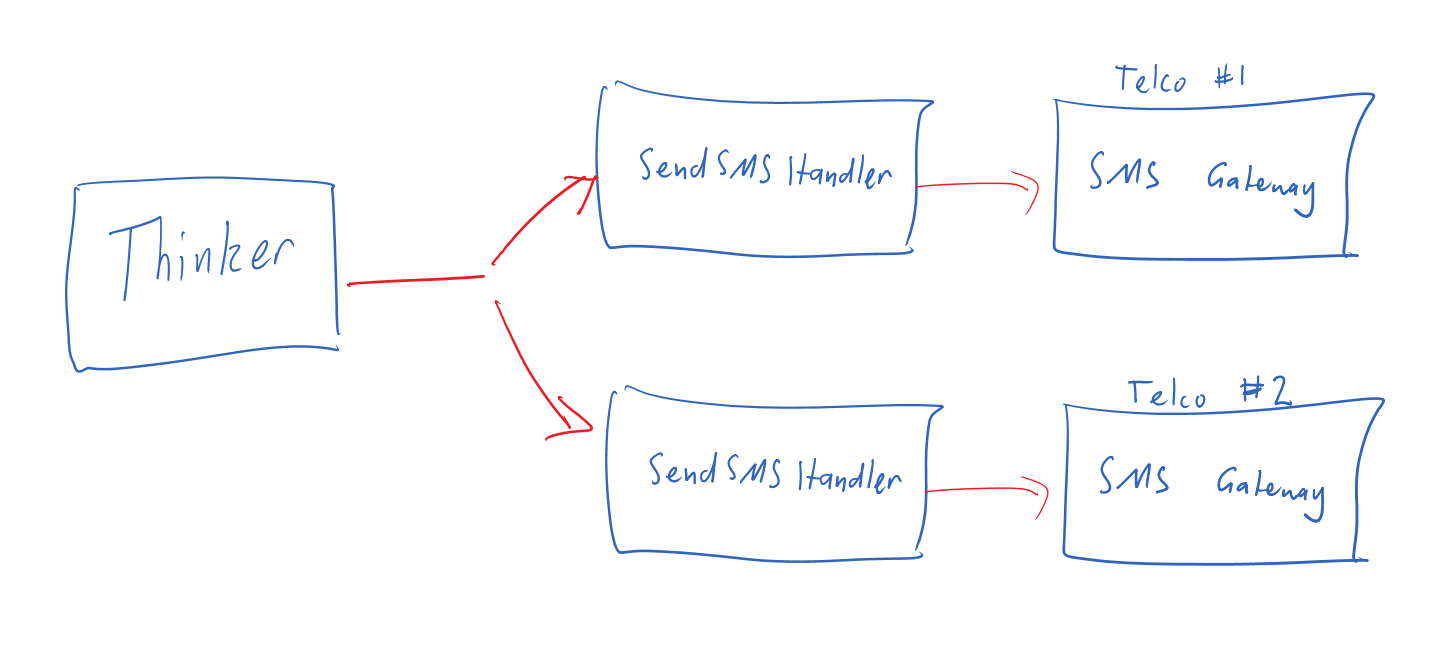
It is, however, important to draw a distinction between choreography and orchestration. If the system that will perform the action makes the decision, it’s choreography. If the system that will perform the action gets told to do it by another system, it’s orchestration.
The key is which system decides that an action should be taken.
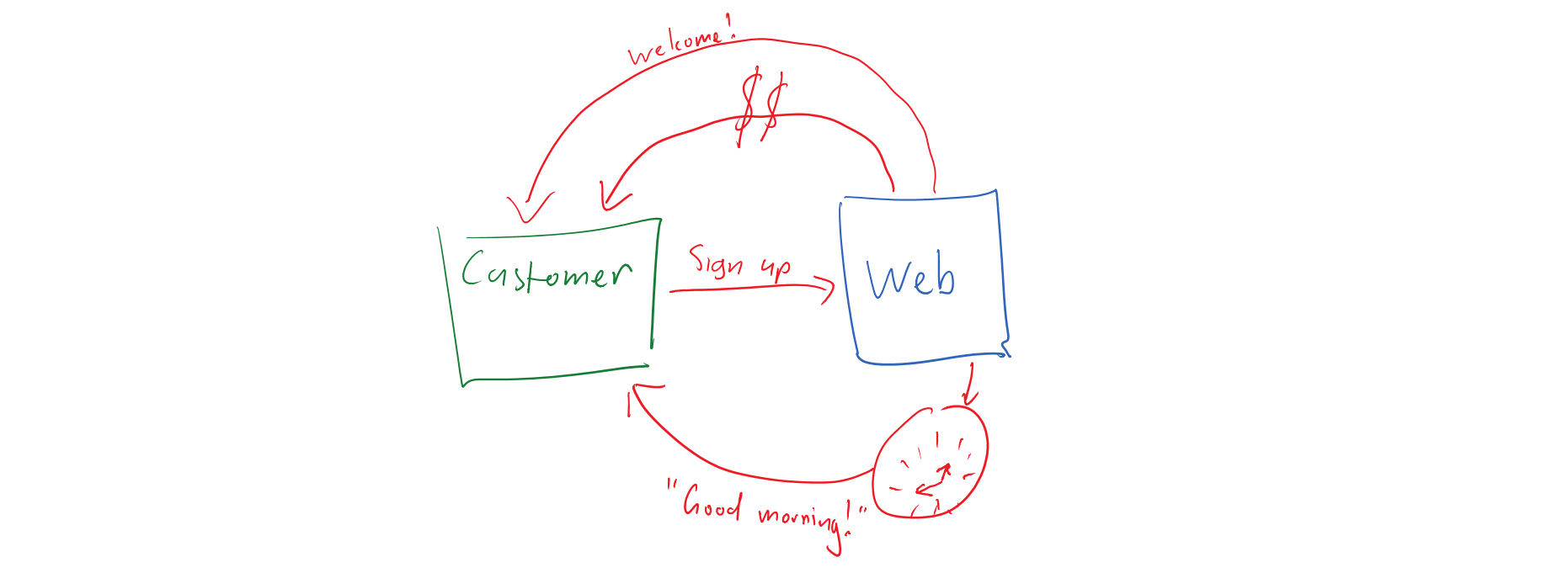
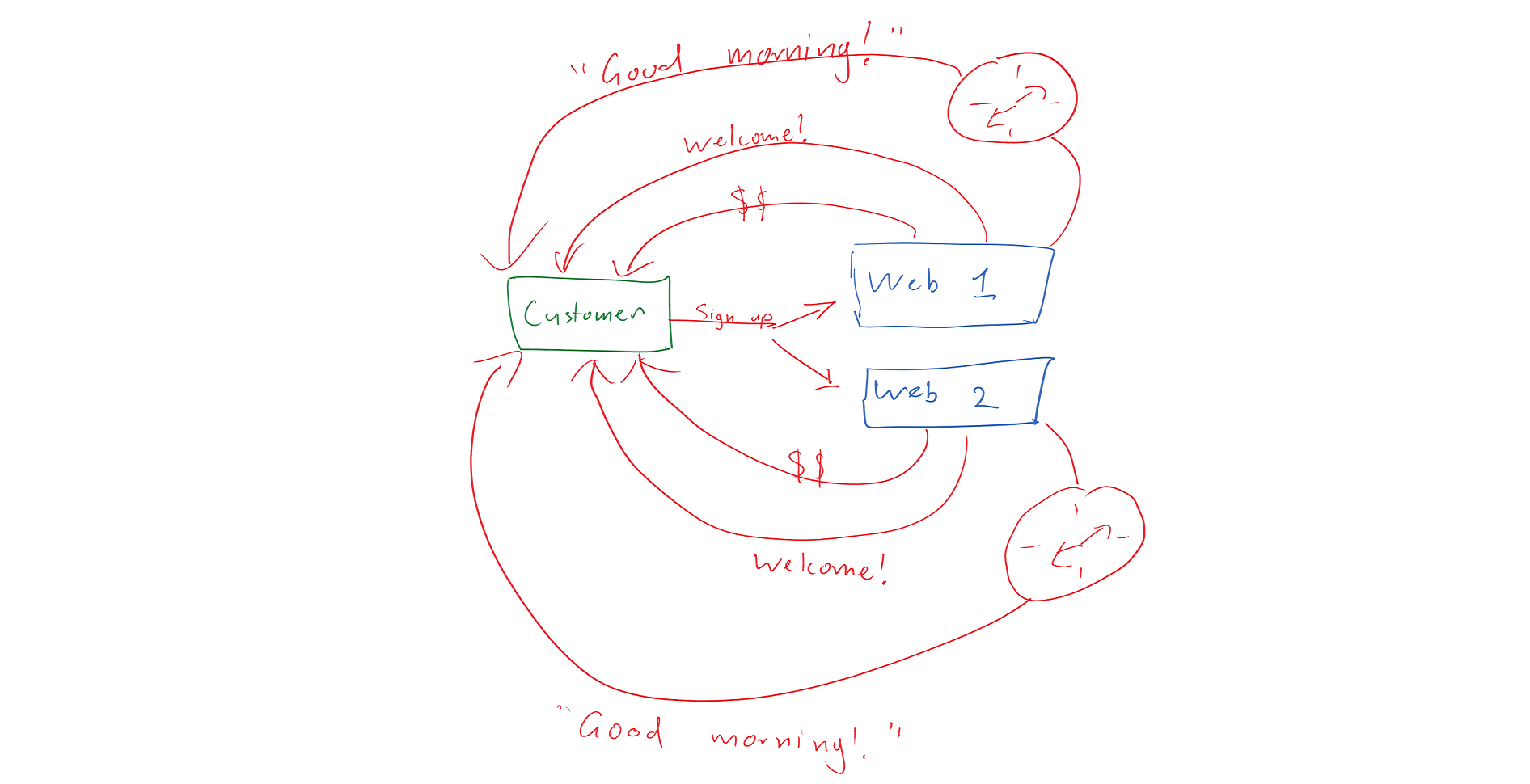
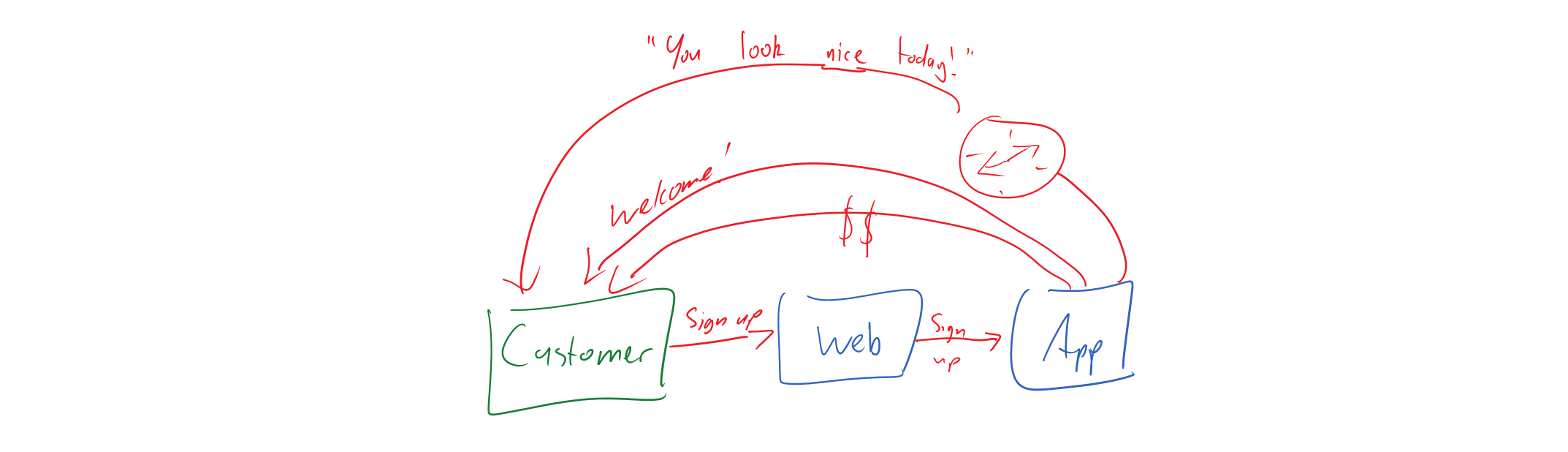
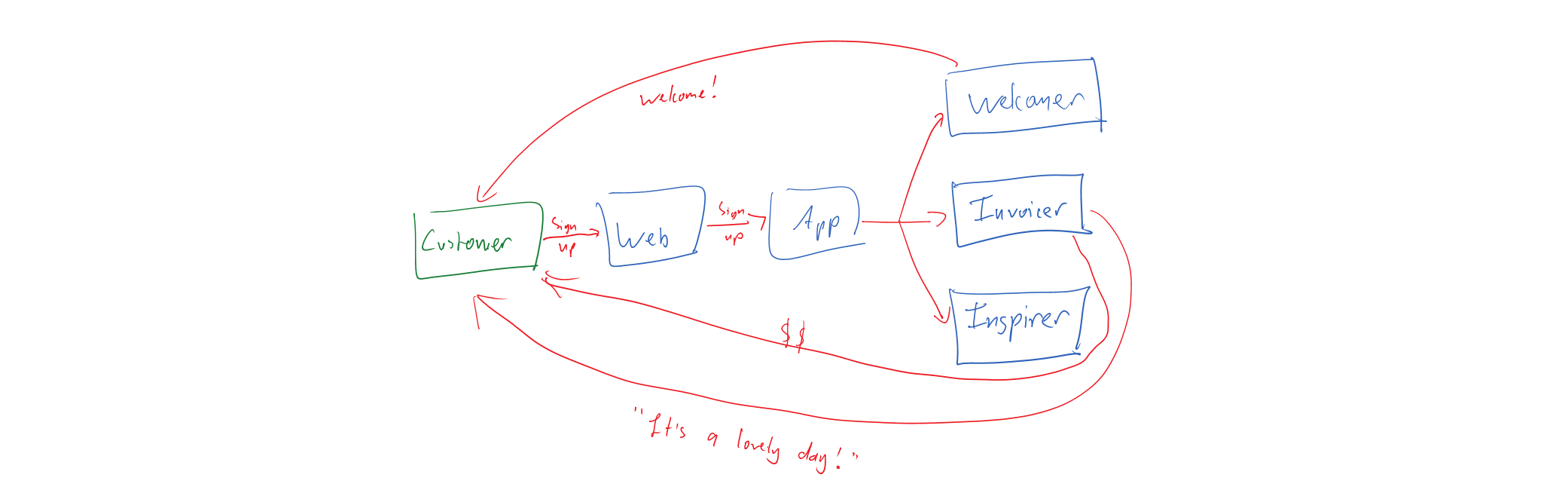
- Choreography is when a system takes independent action of its own volution as a result of the action of another system.
- Orchestration is when some kind of process manager instructs a system to take action, usually as a result of an action of another system.
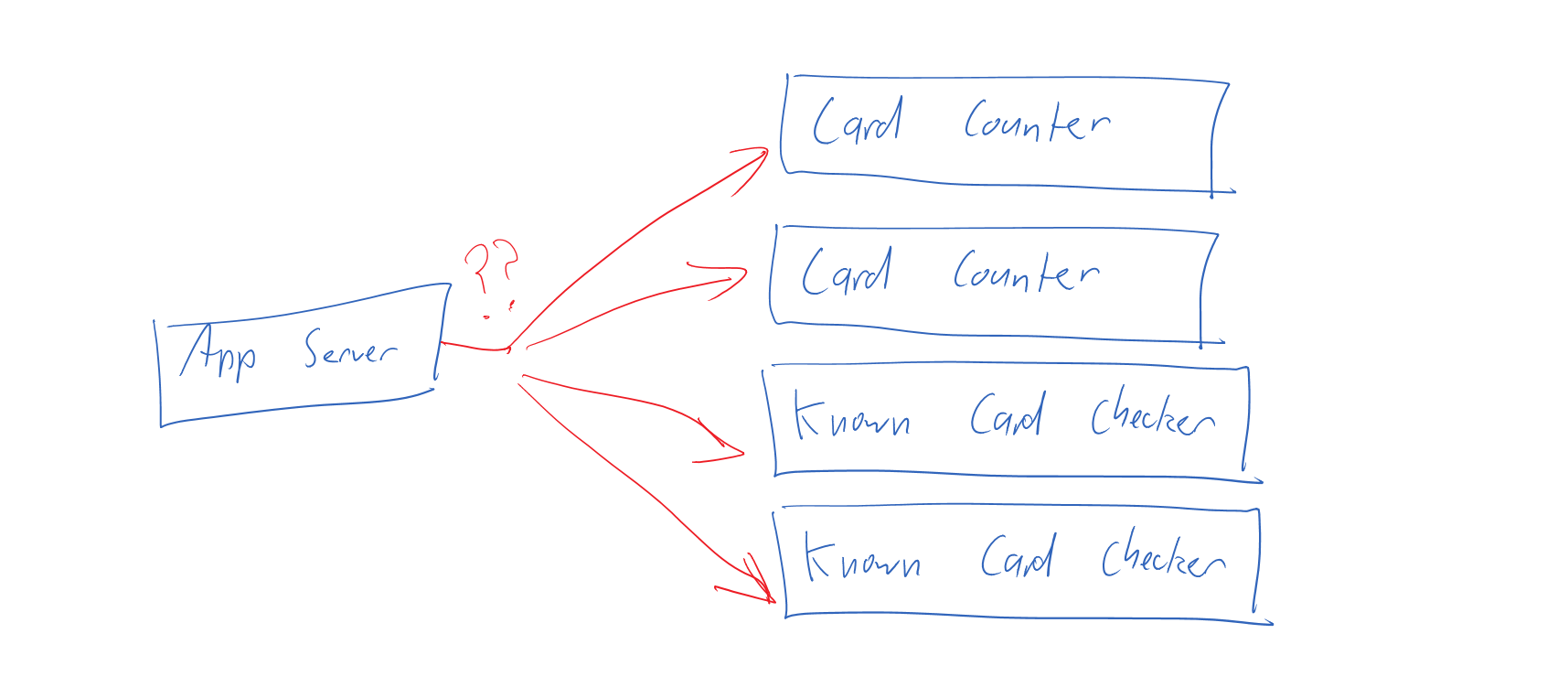
So which should I use? How do I decide?
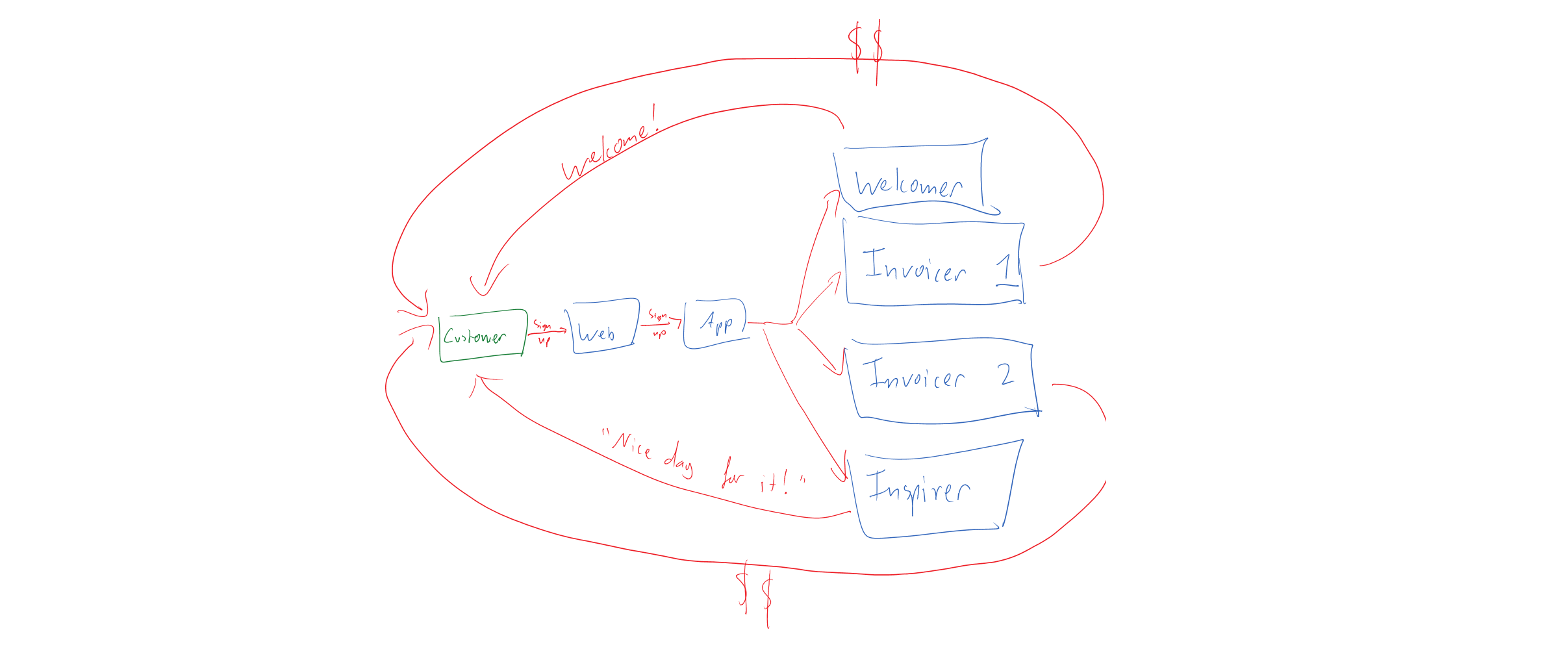
This brings us to the question of which we should use and when. A simple rule of thumb is if a business process has a name and some state, it’s an entity. When we speak in terms of rules, e.g. “When a customer signs up, send them a welcome email” then choreography is a good candidate. When we speak in terms of process names, e.g. “Your application process is at the ‘Pending approval’ stage” then it’s a good hint that we’re in orchestration territory.
How do we model an orchestrated process?
We’ve already established that an orchestrated process has both state (“Where is this process up to?”) and behaviour (i.e. state transitions). This sounds suspiciously like… a domain entity.
If we accept that our process is a domain entity, many things fall into place. For one, we can query its state, and we can instruct it to change state. It can also refuse to undergo an invalid state transition, e.g. a call to a LoanApplicationProcess.Approve(...) should probably fail if LoanApplicationProcess.CurrentState == LoanApplicationState.NotYetSubmitted.
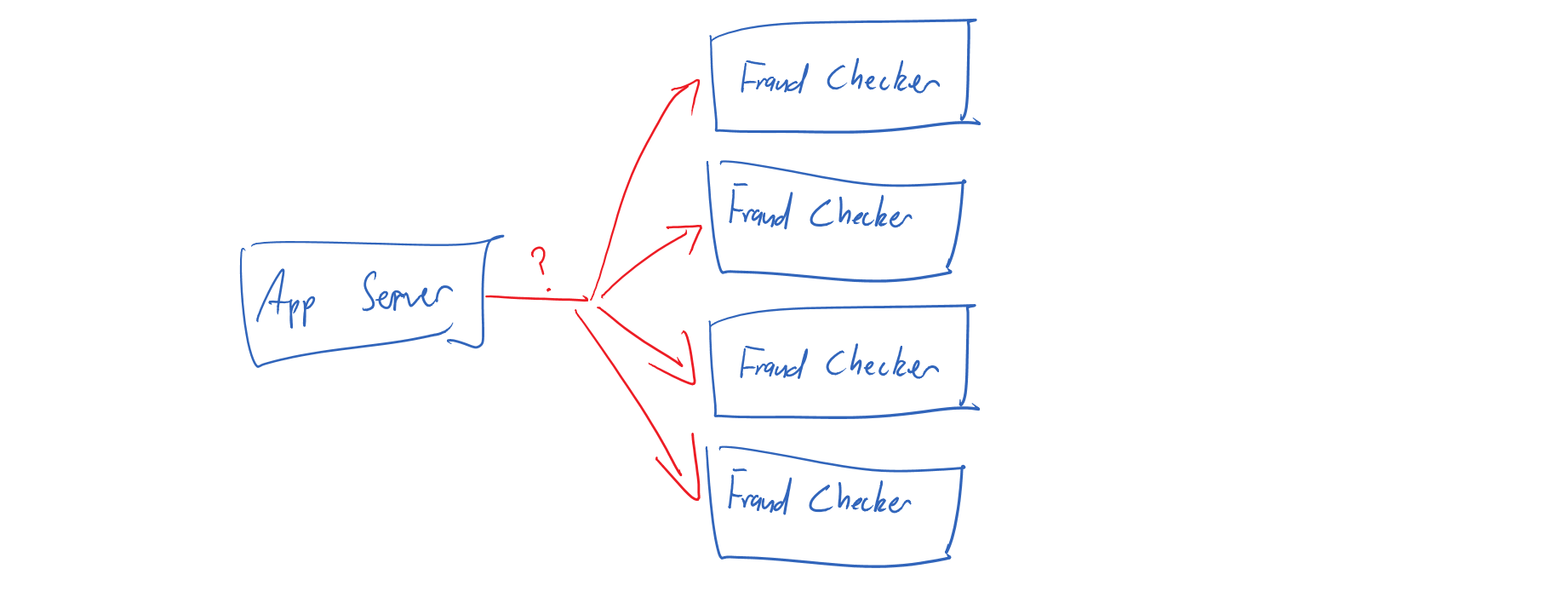
Doesn’t process orchestration mean I need an enterprise service bus? Should I get one?
No matter what problem you have, an enterprise service bus can always find a way to make it worse.
Thinking purely in terms of domain-driven design, we already have all of the puzzle pieces we need to solve this problem: domain logic and state persistence. This sounds suspiciously like it woudld fit into the normal structure of our domain model. We presumably have a repository implementation of some sort, and a persistence layer.
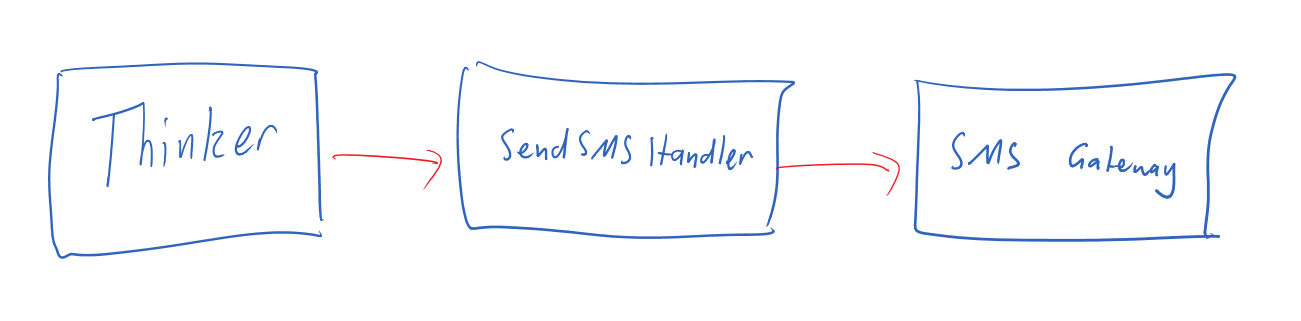
When our process needs to respond to an external event, we can use a vanilla event handler to hydrate our process instance and dispatch the event to the process.
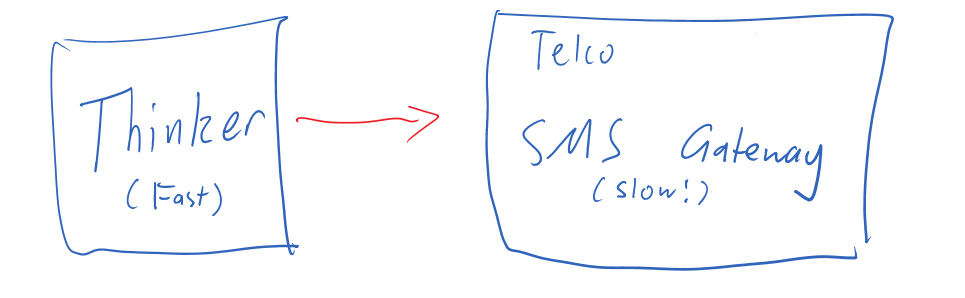
The only missing piece is when we have a process that is dependent on time, which can be solved quite easily with a metronome which hydrates every non-finished process entity and calls a .TimePasses(DateTimeOffset now) method on it.